Before deploying our DRL-powered distributed storage allocation system, we invested in an intensive training phase to ensure our agent’s efficiency and stability.
🎯 By carefully tuning the hyperparameters α (learning rate), β (latency weight), and γ (discount factor), we enabled the agent to align with specific performance objectives. For example:
- To minimize storage and retrieval latency, we found that setting α = γ = 0 and a positive β yielded optimal behavior.
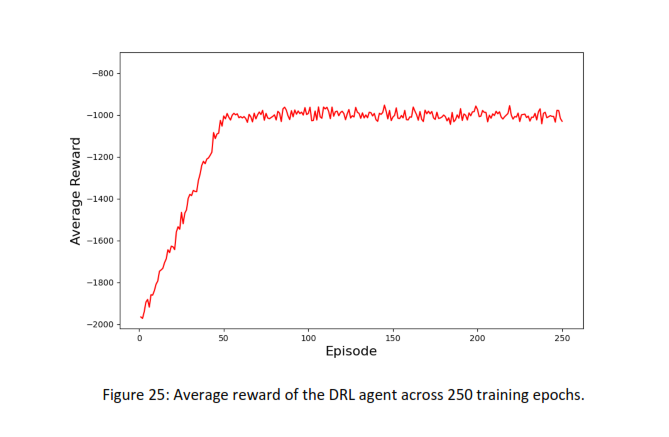
📊 The training was run over 250 epochs, each handling 500 storage requests based on our experimental setup.
✅ One notable result:
With α = 0.005 and γ = 0.9, the agent’s cumulative reward converged in just ~50 episodes, showcasing robust learning and system stability.
Stay tuned as we move from training to real-world deployment! 💡
#AI #ReinforcementLearning #DistributedSystems #DeepLearning #TechInnovation #AllegroProject #MachineLearning #SmartStorage